 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEponaV2: Driving World Model with Comprehensive Future Reasoning
May 14, 2026Data scaling plays a pivotal role in the pursuit of general intelligence. However, the prevailing perception-planning paradigm in autonomous driving relies heavily on expensive manual annotations to supervise trajectory planning, which severely limits its scalability. Conversely, although existing perception-free driving world models achieve impressive driving performance, their real-world reasoning ability for planning is solely built on next frame image forecasting. Due to the lack of enough supervision, these models often struggle with comprehensive scene understanding, resulting in unsatisfactory trajectory planning. In this paper, we propose EponaV2, a novel paradigm of driving world models, which achieves high-quality planning with comprehensive future reasoning. Inspired by how human drivers anticipate 3D geometry and semantics, we train our model to forecast more comprehensive future representations, which can be additionally decoded to future geometry and semantic maps. Extracting the 3D and semantic modalities enables our model to deeply understand the surrounding environment, and the future prediction task significantly enhances the real-world reasoning capabilities of EponaV2, ultimately leading to improved trajectory planning. Moreover, inspired by the training recipe of Large Language Models (LLMs), we introduce a flow matching group relative policy optimization mechanism to further improve planning accuracy. The state-of-the-art (SOTA) performances of EponaV2 among perception-free models on three NAVSIM benchmarks (+1.3PDMS, +5.5EPDMS) demonstrate the effectiveness of our methods.
MGVQ: Could VQ-VAE Beat VAE? A Generalizable Tokenizer with Multi-group Quantization
Jul 10, 2025



Vector Quantized Variational Autoencoders (VQ-VAEs) are fundamental models that compress continuous visual data into discrete tokens. Existing methods have tried to improve the quantization strategy for better reconstruction quality, however, there still exists a large gap between VQ-VAEs and VAEs. To narrow this gap, we propose \NickName, a novel method to augment the representation capability of discrete codebooks, facilitating easier optimization for codebooks and minimizing information loss, thereby enhancing reconstruction quality. Specifically, we propose to retain the latent dimension to preserve encoded features and incorporate a set of sub-codebooks for quantization. Furthermore, we construct comprehensive zero-shot benchmarks featuring resolutions of 512p and 2k to evaluate the reconstruction performance of existing methods rigorously. \NickName~achieves the \textbf{state-of-the-art performance on both ImageNet and $8$ zero-shot benchmarks} across all VQ-VAEs. Notably, compared with SD-VAE, we outperform them on ImageNet significantly, with rFID $\textbf{0.49}$ v.s. $\textbf{0.91}$, and achieve superior PSNR on all zero-shot benchmarks. These results highlight the superiority of \NickName~in reconstruction and pave the way for preserving fidelity in HD image processing tasks. Code will be publicly available at https://github.com/MKJia/MGVQ.
DrivingWorld: Constructing World Model for Autonomous Driving via Video GPT
Dec 30, 2024



Recent successes in autoregressive (AR) generation models, such as the GPT series in natural language processing, have motivated efforts to replicate this success in visual tasks. Some works attempt to extend this approach to autonomous driving by building video-based world models capable of generating realistic future video sequences and predicting ego states. However, prior works tend to produce unsatisfactory results, as the classic GPT framework is designed to handle 1D contextual information, such as text, and lacks the inherent ability to model the spatial and temporal dynamics essential for video generation. In this paper, we present DrivingWorld, a GPT-style world model for autonomous driving, featuring several spatial-temporal fusion mechanisms. This design enables effective modeling of both spatial and temporal dynamics, facilitating high-fidelity, long-duration video generation. Specifically, we propose a next-state prediction strategy to model temporal coherence between consecutive frames and apply a next-token prediction strategy to capture spatial information within each frame. To further enhance generalization ability, we propose a novel masking strategy and reweighting strategy for token prediction to mitigate long-term drifting issues and enable precise control. Our work demonstrates the ability to produce high-fidelity and consistent video clips of over 40 seconds in duration, which is over 2 times longer than state-of-the-art driving world models. Experiments show that, in contrast to prior works, our method achieves superior visual quality and significantly more accurate controllable future video generation. Our code is available at https://github.com/YvanYin/DrivingWorld.
DrivingWorld: ConstructingWorld Model for Autonomous Driving via Video GPT
Dec 27, 2024Recent successes in autoregressive (AR) generation models, such as the GPT series in natural language processing, have motivated efforts to replicate this success in visual tasks. Some works attempt to extend this approach to autonomous driving by building video-based world models capable of generating realistic future video sequences and predicting ego states. However, prior works tend to produce unsatisfactory results, as the classic GPT framework is designed to handle 1D contextual information, such as text, and lacks the inherent ability to model the spatial and temporal dynamics essential for video generation. In this paper, we present DrivingWorld, a GPT-style world model for autonomous driving, featuring several spatial-temporal fusion mechanisms. This design enables effective modeling of both spatial and temporal dynamics, facilitating high-fidelity, long-duration video generation. Specifically, we propose a next-state prediction strategy to model temporal coherence between consecutive frames and apply a next-token prediction strategy to capture spatial information within each frame. To further enhance generalization ability, we propose a novel masking strategy and reweighting strategy for token prediction to mitigate long-term drifting issues and enable precise control. Our work demonstrates the ability to produce high-fidelity and consistent video clips of over 40 seconds in duration, which is over 2 times longer than state-of-the-art driving world models. Experiments show that, in contrast to prior works, our method achieves superior visual quality and significantly more accurate controllable future video generation. Our code is available at https://github.com/YvanYin/DrivingWorld.
MapEval: Towards Unified, Robust and Efficient SLAM Map Evaluation Framework
Nov 26, 2024



Evaluating massive-scale point cloud maps in Simultaneous Localization and Mapping (SLAM) remains challenging, primarily due to the absence of unified, robust and efficient evaluation frameworks. We present MapEval, an open-source framework for comprehensive quality assessment of point cloud maps, specifically addressing SLAM scenarios where ground truth map is inherently sparse compared to the mapped environment. Through systematic analysis of existing evaluation metrics in SLAM applications, we identify their fundamental limitations and establish clear guidelines for consistent map quality assessment. Building upon these insights, we propose a novel Gaussian-approximated Wasserstein distance in voxelized space, enabling two complementary metrics under the same error standard: Voxelized Average Wasserstein Distance (AWD) for global geometric accuracy and Spatial Consistency Score (SCS) for local consistency evaluation. This theoretical foundation leads to significant improvements in both robustness against noise and computational efficiency compared to conventional metrics. Extensive experiments on both simulated and real-world datasets demonstrate that MapEval achieves at least \SI{100}{}-\SI{500}{} times faster while maintaining evaluation integrity. The MapEval library\footnote{\texttt{https://github.com/JokerJohn/Cloud\_Map\_Evaluation}} will be publicly available to promote standardized map evaluation practices in the robotics community.
BeautyMap: Binary-Encoded Adaptable Ground Matrix for Dynamic Points Removal in Global Maps
May 12, 2024



Global point clouds that correctly represent the static environment features can facilitate accurate localization and robust path planning. However, dynamic objects introduce undesired ghost tracks that are mixed up with the static environment. Existing dynamic removal methods normally fail to balance the performance in computational efficiency and accuracy. In response, we present BeautyMap to efficiently remove the dynamic points while retaining static features for high-fidelity global maps. Our approach utilizes a binary-encoded matrix to efficiently extract the environment features. With a bit-wise comparison between matrices of each frame and the corresponding map region, we can extract potential dynamic regions. Then we use coarse to fine hierarchical segmentation of the $z$-axis to handle terrain variations. The final static restoration module accounts for the range-visibility of each single scan and protects static points out of sight. Comparative experiments underscore BeautyMap's superior performance in both accuracy and efficiency against other dynamic points removal methods. The code is open-sourced at https://github.com/MKJia/BeautyMap.
A Dynamic Points Removal Benchmark in Point Cloud Maps
Jul 14, 2023



In the field of robotics, the point cloud has become an essential map representation. From the perspective of downstream tasks like localization and global path planning, points corresponding to dynamic objects will adversely affect their performance. Existing methods for removing dynamic points in point clouds often lack clarity in comparative evaluations and comprehensive analysis. Therefore, we propose an easy-to-extend unified benchmarking framework for evaluating techniques for removing dynamic points in maps. It includes refactored state-of-art methods and novel metrics to analyze the limitations of these approaches. This enables researchers to dive deep into the underlying reasons behind these limitations. The benchmark makes use of several datasets with different sensor types. All the code and datasets related to our study are publicly available for further development and utilization.
Fast and Robust Bin-picking System for Densely Piled Industrial Objects
Dec 04, 2020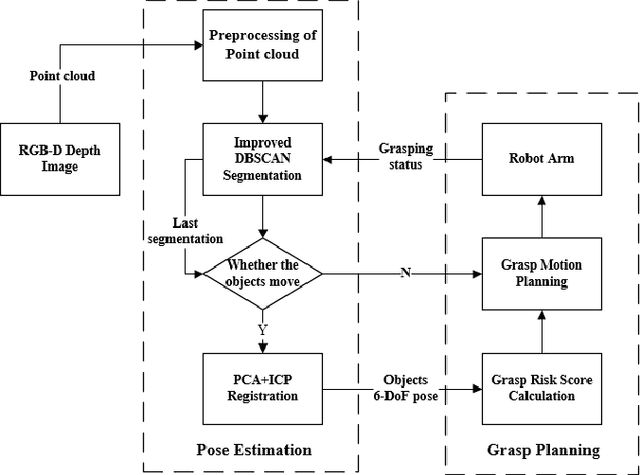



Objects grasping, also known as the bin-picking, is one of the most common tasks faced by industrial robots. While much work has been done in related topics, grasping randomly piled objects still remains a challenge because much of the existing work either lack robustness or costs too much resource. In this paper, we develop a fast and robust bin-picking system for grasping densely piled objects adaptively and safely. The proposed system starts with point cloud segmentation using improved density-based spatial clustering of application with noise (DBSCAN) algorithm, which is improved by combining the region growing algorithm and using Octree to speed up the calculation. The system then uses principle component analysis (PCA) for coarse registration and iterative closest point (ICP) for fine registration. We propose a grasp risk score (GRS) to evaluate each object by the collision probability, the stability of the object, and the whole pile's stability. Through real tests with the Anno robot, our method is verified to be advanced in speed and robustness.